
Qual algoritmo de previsão é o mais adequado para people analytics?

Um guia para
escolher seu
modelo preditivo
Um dos tópicos mais falados na área de People Analytics é a abordagem preditiva – na qual não queremos somente entender o que aconteceu, mas principalmente entender o que acontecerá. O objetivo deste artigo é discutir as boas práticas ao escolher um modelo preditivo, mostrando as principais diferenças entre os tipos mais utilizados além das consequências práticas e éticas de cada um deles.
O tópico de Machine Learning e análise preditiva tem se mostrado cada vez mais presente em nosso cotidiano e vem sendo aplicado na recomendação de filmes pelo Netflix, previsão de perda de clientes (Customer Churn), diagnósticos médicos (por exemplo, Babylon Health) e em uma variedade de outros campos (este vídeo mostra algumas destas aplicações). Além dos exemplos acima, diversas empresas começaram a aplicar esta abordagem preditiva na área de Recursos Humanos, como por exemplo em projetos que tem como objetivo prever saída de funcionários (Turnover), ou em projetos focados na redução de acidentes de trabalho, ou até mesmo em projetos que visam prever a performance de uma pessoa a partir de dados de recrutamento e seleção.
Contudo, ao aplicar estes modelos preditivos para gestão de pessoas, existem cuidados práticos e éticos que devem ser levados em consideração, dado que estes projetos lidam com pessoas e buscam resolver um problema de negócio. Desta maneira, um dos pontos delicados nestes projetos é justamente a escolha do modelo a ser utilizado. Pensando nisso, decidimos escrever um artigo para mostrar quais são as principais diferenças entre os tipos de modelos preditivos e os cuidados que devem ser tomados ao escolhê-los. Tangibilizaremos as diferenças ao longo de um case de Turnover e ao final daremos algumas dicas práticas e uma lista dos principais modelos utilizados, suas vantagens e desvantagens.
Em geral, os modelos preditivos de Machine Learning estão dentro de um nicho chamado de Aprendizagem Supervisionada, no qual o intuito é prever uma variável específica (como por exemplo, a saída do funcionário ou performance). O esquema abaixo mostra como estes modelos funcionam:
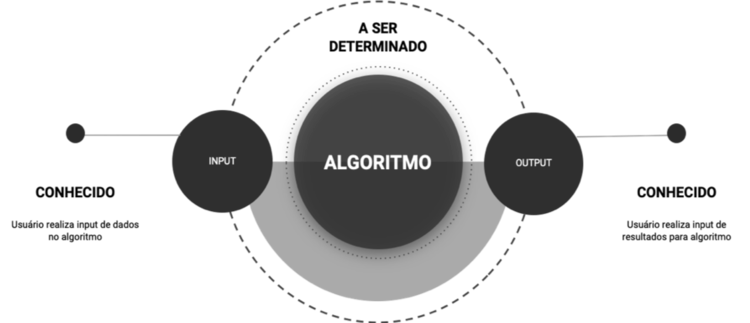
Os dados são inseridos no algoritmo para o problema específico que será analisado e, a partir disso, o algoritmo irá encontrar os padrões que relacionam os dados relevantes (input) com o que queremos prever (output).
Vamos exemplificar com um modelo preditivo de Turnover: os inputs são dados cadastrais, performance, satisfação e outras informações que sejam relevantes dos colaboradores. Além disso, é necessário explicitar qual a variável que desejamos prever, nesse caso é a variável que indica se o funcionário saiu ou não. A partir destes dados, o algoritmo encontrará as associações entre o input e output e assim conseguirá prever as chances dos demais funcionários saírem dadas as características dos mesmos.
Contudo, cada modelo fará estas associações de modos distintos e é exatamente a maneira de fazê-las que define o modelo preditivo em si. Alguns destes modelos buscarão ligações mais simples entre as variáveis e outros buscarão ligações mais complexas. A decisão sobre qual modelo é o mais adequado à situação cabe justamente ao profissional de People Analytics, que tem conhecimento sobre o problema de negócio e os efeitos de escolher um caminho em detrimento de outros.
“CADA ALGORITMO FARÁ ASSOCIAÇÕES ENTRE O INPUT E OUTPUT DE MODO DISTINTO, E É EXATAMENTE A MANEIRA DE FAZÊ-LAS QUE DEFINE O MODELO PREDITIVO EM SI. ALGUNS DESTES MODELOS BUSCARÃO LIGAÇÕES MAIS SIMPLES ENTRE AS VARIÁVEIS E OUTROS BUSCARÃO LIGAÇÕES MAIS COMPLEXAS”
PREVENDO SAÍDA DE FUNCIONÁRIOS
PREVENDO SAÍDA DE FUNCIONÁRIOS
Imagine que uma empresa do ramo de tecnologia está com um alto nível de Turnover e deseja prever quais funcionários irão sair a fim de definir um plano de ação para resolver esse problema de negócio. Para isso, eles possuem os seguintes dados:
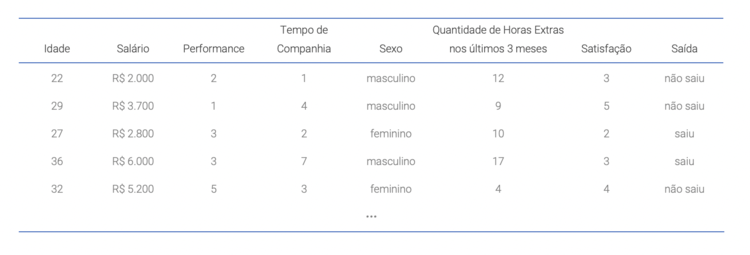
Basicamente, é necessário construir um modelo preditivo que faça associações entre as variáveis disponíveis com a informação de saída dos colaboradores. Porém qual seria o melhor modelo a ser utilizado neste caso? A resposta é: depende do que queremos dizer com “melhor modelo”.
Podemos começar utilizando modelos que fazem associações mais simples entre os inputs e o output, como por exemplo a Regressão Logística. Este modelo calcula a probabilidade de um evento acontecer dada qualquer alteração em outra variável, ou seja, ele mostra o quanto a probabilidade de saída dos colaboradores se altera conforme as demais variáveis se alteram. Aplicando este modelo preditivo, podemos entender o impacto de cada variável na saída dos colaboradores.
O gráfico abaixo mostra justamente as associações de cada um dos inputs mencionados com o Turnover:
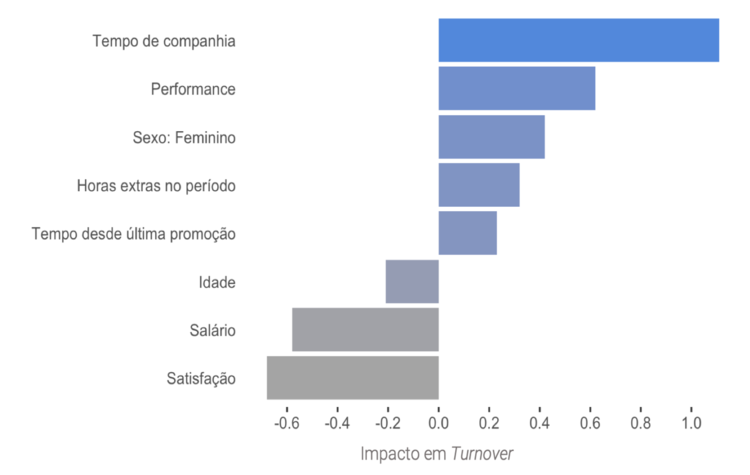
O resultado do modelo mostra que a variável que mais impacta a saída de funcionários (medido em log-odds) é o tempo de companhia. A probabilidade de o funcionário sair aumenta à medida que o tempo de companhia aumenta. A variável satisfação também possui um impacto relativamente alto, mas na direção oposta, ou seja, a probabilidade de saída diminui com o aumento da satisfação do colaborador. Outra associação interessante de ser analisada é o sexo: o fato de ser do sexo feminino aumenta a probabilidade de saída se comparado com funcionários do sexo masculino. Desta maneira, o resultado do algoritmo de Regressão Logística mostra não somente o quanto os inputs afetam o Turnover, mas também como eles se relacionam.
Uma vez que o algoritmo aprendeu estas associações, o objetivo é que ele consiga prever a saída ou não dos funcionários no futuro. Para testar sua capacidade de previsão, basta aplicar este mesmo algoritmo em um conjunto de dados que não foram utilizados para construí-lo e comparar a previsão gerada por ele com o resultado real, como pode ser observado abaixo:

O algoritmo utilizará as associações que ele aprendeu anteriormente para prever se cada uma dessas pessoas sairá ou não. Em alguns casos ele acertará a previsão e em outros casos ele errará. Comparando a previsão com o resultado real para toda a base de dados desse exemplo, o algoritmo obteve uma acurácia de 74%, indicando que ele acerta em 74% das vezes ao prever se os colaboradores saem ou ficam.
Além disso, é possível entender os motivos da previsão do algoritmo. Por exemplo, analisando o primeiro caso da tabela acima vemos que, dado que o funcionário possui uma performance alta, tempo de companhia alto e é do sexo feminino, a previsão é de que a pessoa sairá, visto que estes fatores aumentam a probabilidade de saída. Desta maneira, algoritmos que fazem associações mais simples, permitem não apenas prever, mas também entender o por quê da previsão gerada.
“ALGORITMOS QUE FAZEM ASSOCIAÇÕES MAIS SIMPLES, PERMITEM NÃO APENAS PREVER, MAS TAMBÉM ENTENDER O POR QUÊ DA PREVISÃO GERADA.”
Vamos partir para uma segunda aplicação usando os mesmos dados, porém um modelo mais flexível e consequentemente mais complexo: Redes Neurais Artificiais. Este algoritmo imita o comportamento de nosso cérebro, no qual a mensagem oriunda dos inputs passa por camadas de neurônios e estes capturam as associações entre variáveis para prever o output.
O resultado das Redes Neurais Artificiais é difícil de compreender, talvez seja por isso que o processamento desse tipo de modelo sejam descritos como uma “caixa-preta”, dada a complexidade de entender quais são exatamente as associações que utilizou para prever o output. O que geralmente é feito após aplicar estes algoritmos que fazem associações mais profundas é analisar a performance preditiva e a importância que cada variável teve na previsão feita.
Assim como foi feito com a Regressão Logística, aplicamos o resultado deste algoritmo em um conjunto de dados de teste e comparamos o resultado previsto pelo algoritmo com o resultado real, obtendo uma acurácia de 86%. Comparando com a Regressão Logística, observa-se que a acurácia das Redes Neurais foi significativamente maior, se mostrando como um modelo melhor como preditor de Turnover.
O gráfico abaixo mostra a importância de cada variável na predição realizada pelas Redes Neurais:
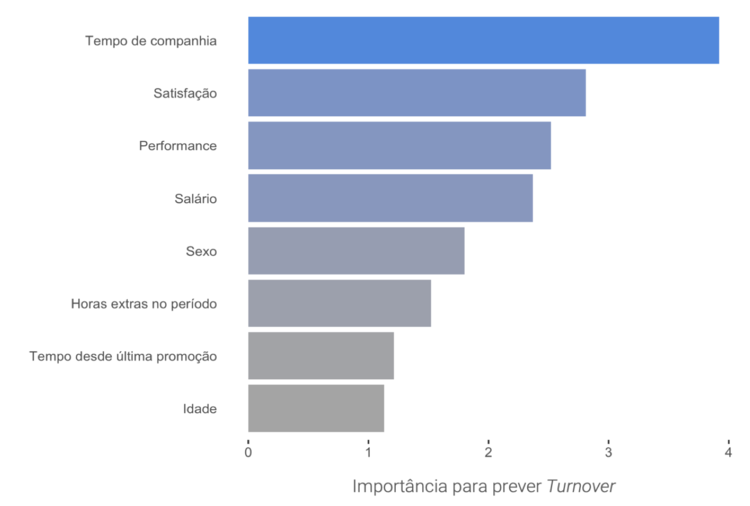
A variável mais importante para prever Turnover foi o tempo de companhia, isto é, existe uma associação muito forte entre ela e a saída dos colaboradores. Porém, não é possível afirmar nada em relação ao tipo de associação que existe entre o tempo de companhia e o Turnover, fazendo com que não saibamos se os funcionários tendem a sair mais ou menos à medida que estão há mais tempo na empresa. Assim, estes modelos que fazem associações mais complexas, mostram o quanto cada variável afeta o output, mas não mostram como elas fazem isso.
“ALGORITMOS QUE FAZEM ASSOCIAÇÕES MAIS COMPLEXAS TENDEM A SER MAIS ACURADOS E MOSTRAM O QUANTO CADA VARIÁVEL AFETA O OUTPUT, MAS NÃO MOSTRAM A MANEIRA QUE ESTÃO ASSOCIADAS”

ABRINDO A CAIXA PRETA
Um dos tópicos mais discutidos em Machine Learning atualmente é a questão de interpretabilidade de algoritmos que fazem associações mais complexas, inclusive na utilização de algoritmos que trabalham reconhecimento de imagens. Diversas técnicas como Efeitos Locais Acumulados, Interação entre variáveis e SHAP-values estão sendo utilizadas para compreender como o input e o output se relacionam, ou ainda para entender qual a interação entre os inputs para prever o output. Além disso, diversas pesquisas vêm buscando definir o que é interpretabilidade em algoritmos e quais os procedimentos para testar se o modelo é realmente interpretável ou não.
Logo, não existe um modelo “melhor” para ajudar a empresa a diminuir seu Turnover, e sim o mais adequado sob a ótica de problema de negócio O primeiro modelo, que fez associações mais simples, possui uma capacidade de previsão menor e uma facilidade de interpretação maior, enquanto o segundo modelo, que fez associações mais complexas, possui uma capacidade de previsão maior, mas uma interpretabilidade menor. Se utilizarmos o primeiro, será possível entender as associações que fazem os colaboradores saírem e teremos uma direção de onde atuar para reter estes colaboradores – caso esse seja o desejo. Se utilizarmos o segundo modelo, iremos prever corretamente uma maior quantidade dos casos, porém não saberemos quais as associações explicam a saída ou não dos colaboradores, dificultando na definição de um plano de ação para diminuição do Turnover.
ACURÁCIA OU INTERPRETABILIDADE
Dentro da área de Machine Learning, um dos pontos mais discutidos ao construir um modelo preditivo é a escolha entre acurácia e interpretabilidade. Geralmente, algoritmos que possuem maior interpretabilidade possuem menor acurácia e algoritmos com maior acurácia tendem a ser menos interpretáveis. Desta maneira, no momento de construir um algoritmo na área de People analytics, um dos pontos mais delicados é definir se o algoritmo será mais acurado ou mais interpretável.
O primeiro ponto a se considerar nessa escolha é o aspecto prático: o que é mais importante, entender o problema para resolvê-lo ou somente prevê-lo? Em geral, estamos falando de um problema de negócio que exige algum tipo de ação para resolvê-lo, assim, ter um algoritmo extremamente acurado mas com baixa interpretabilidade dificulta a tomada de decisão, fazendo com que o problema se mantenha mesmo que consigamos prever quando irá acontecer. Desta maneira, modelos que fazem associações mais simples são benéficos em termos de direcionamento na decisão a ser tomada, além de que muitas vezes sua capacidade de previsão é próxima de um algoritmo que faz associações mais complexas.
“MODELOS QUE FAZEM ASSOCIAÇÕES MAIS SIMPLES SÃO BENÉFICOS EM TERMOS DE DIRECIONAMENTO NA TOMADA DE DECISÃO, ALÉM DE QUE MUITAS VEZES SUA CAPACIDADE DE PREVISÃO É PRÓXIMA DE UM ALGORITMO QUE FAZ ASSOCIAÇÕES MAIS COMPLEXAS.”

REPRODUÇÃO DE VIESES
Em 2014, a Amazon decidiu construir um modelo preditivo para a área de Recrutamento e Seleção cujo objetivo era dar uma nota de 1 a 5 para cada um dos candidatos do processo seletivo a partir de seus currículos, com intuito de automatizar o processo de recrutamento. Este algoritmo foi implementado dentro da empresa, contudo em 2015 eles notaram que os candidatos não estavam sendo avaliados de uma maneira justa, pois detectaram um viés de gênero nas predições, onde homens tinham notas maiores que mulheres. A causa disso foi que os desenvolvedores utilizaram como input do modelo currículos de 2004 a 2014, sendo que ao longo deste período a maioria dos currículos eram de homens, fazendo com que o algoritmo penalizasse pessoas do sexo feminino na pontuação final. Isto evidencia o cuidado necessário ao utilizar algoritmos “caixa-preta” em decisões relacionadas às pessoas, visto que o modelo reproduzirá o viés que se encontram nos dados inseridos.
O segundo ponto a ser considerado é o aspecto ético. Quando se trata de People Analytics (e também outras áreas que envolvem pessoas) é necessário levar em consideração que estamos lidando com vidas, fazendo com que seja fundamental embasar as decisões que serão tomadas em relação a elas. Algoritmos de Machine Learning são ótimos para reproduzir padrões, porém se estes padrões são enviesados, o algoritmo também será. Por exemplo, ao construir um modelo preditivo de recrutamento e seleção não adianta apenas prever bem quem deve ser contratado e quem não deve – é importante entender se há algum viés, como racial ou de gênero dentro da empresa pois o algoritmo apenas reproduzirá este viés com uma intensidade maior. Portanto, é fundamental entender o por quê das predições, fazendo com que modelos interpretáveis sejam mais apropriados.
O terceiro fator relevante é o aspecto legal. Cada vez mais está sendo discutido legalmente a utilização destes algoritmos “caixa-preta” na tomada de decisões relacionadas a pessoas. Na União Europeia já existe o “Direito à Explicação”, no qual é dado o direito às pessoas de receberem uma explicação do por quê da previsão do algoritmo quando ele afeta significativamente o indivíduo, como por exemplo, em algoritmos de recrutamento e seleção ou algoritmos de concessão de crédito. Esta discussão está cada vez mais latente na Europa e nos Estados Unidos e a tendência é que chegue em breve no mundo todo. Portanto, utilizar modelos que fazem associações mais complexas e menos interpretáveis pode causar danos legais, dado a dificuldade de interpretar o motivo da predição no nível individual.
ESCOLHENDO O MELHOR ALGORITMO
No momento de escolher qual modelo preditivo será utilizado, é importante levar em consideração os três pontos citados acima, além de buscar o algoritmo que melhor se encaixa no problema de negócio que está sendo analisado. Em geral, uma boa prática é aplicar mais de um modelo preditivo dando preferência para algoritmos interpretáveis em um primeiro momento, com intuito de entender melhor as associações entre os inputs e o output. Caso não seja observada nenhuma relação que possa ser explicada por um viés, é possível utilizar modelos que fazem associações mais complexas, desde que utilize as técnicas mais recentes para entender minimamente as associações que estão sendo feitas dentro do algoritmo “caixa-preta”. Por fim, conheça seus dados. Uma boa análise exploratória já pode indicar possíveis vieses e te ajuda a evitar algoritmos enviesados.
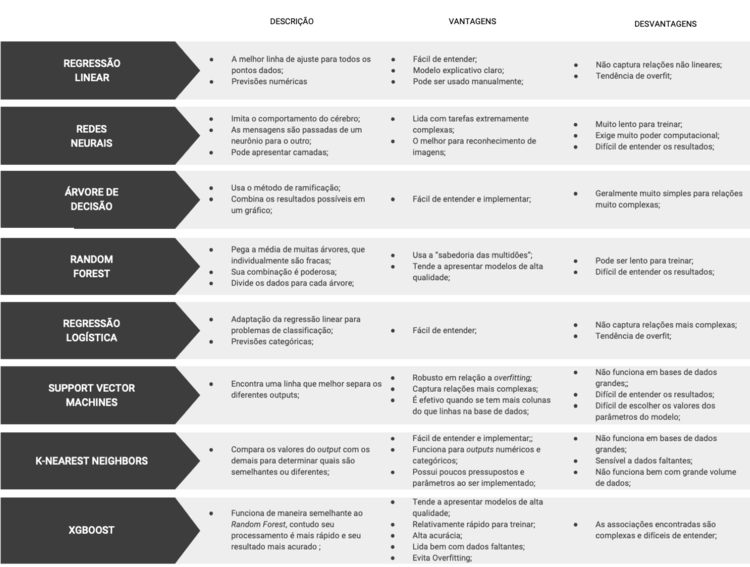
Para ajudar na escolha dos algoritmos, separamos uma lista de modelos de Machine Learning que geralmente são utilizados, trazendo uma breve descrição sobre eles, suas principais vantagens e desvantagens.
DIEGO LIBERATO
Quer ajuda para escolher o melhor algoritmo de previsão para sua empresa? Entre em contato com nosso time de consultoria.